
SEO excerpt: Anthropic has published a more explicit rulebook for what its frontier coding and cybersecurity models should block, monitor, and allow. For DevOps, platform, and security teams, the important development is not just Fable 5’s return, but a draft severity framework that could shape how AI jailbreaks are scored across vendors and governments.
MUMBAI, July 4, 2026, 12:04 p.m. IST – Anthropic has moved its Fable 5 controversy from access restoration into policy definition, publishing a detailed breakdown of the cyber safeguards around the model and a draft framework for grading how dangerous AI jailbreaks actually are.
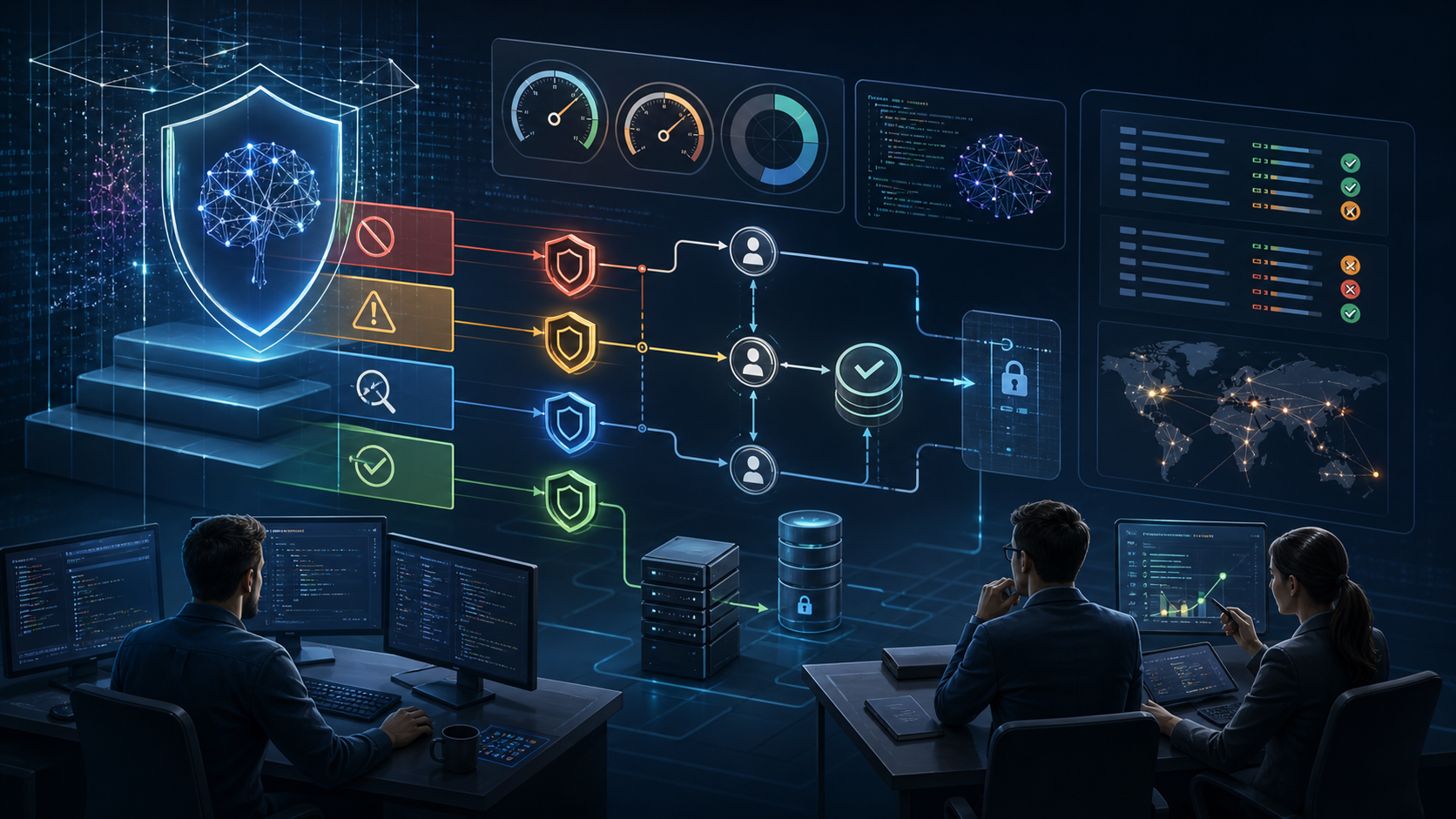
The company said July 2 that Claude Fable 5 is back online globally and that it is now spelling out which categories of cybersecurity activity its classifiers are meant to block, which ones they may monitor, and which defensive tasks should remain available. Anthropic is also proposing a Cyber Jailbreak Severity scale that scores a jailbreak by capability gain, breadth, ease of weaponization, and discoverability.
Why this matters now is straightforward. In the last three weeks, frontier AI model access has become an operational issue rather than an abstract policy debate. Anthropic had to suspend Fable 5 and Mythos 5 after a U.S. government directive in mid-June, then restore Fable 5 after new safeguards were reviewed. The latest post is the company’s attempt to show security teams, cloud partners, and regulators what a more explicit control model could look like.
What Anthropic confirmed
In its July 2 announcement, Anthropic divided Fable 5’s cyber-related behavior into four buckets: prohibited use, high-risk dual use, low-risk dual use, and benign use. The company said clearly harmful actions such as malware development, command-and-control, destructive sabotage, and exfiltration should be blocked. It also said high-risk dual-use work, including penetration testing, exploit development, and privilege-escalation workflows, is expected to be blocked for now until access controls improve.
At the same time, Anthropic said it does not intend to block routine defensive work such as secure coding, debugging, patch management, log analysis, incident response, general cloud administration, and fixing already identified vulnerabilities. That distinction is important for engineering teams because it sets clearer expectations for where a frontier coding model may refuse work in a security-heavy pipeline.
The company also disclosed a draft Cyber Jailbreak Severity scale, or CJS, running from informational findings to critical severity. Anthropic’s proposal scores a jailbreak on four axes: how much offensive capability it adds, how broadly the same technique generalizes, how easy it is to weaponize, and how easy it is for attackers to discover. Anthropic said it has been developing that framework with Glasswing partners including Amazon, Microsoft, and Google, and opened a HackerOne program for researchers to submit cyber jailbreaks.
Why the framework matters for GravityDevOps readers
For developers and platform teams, the practical problem is not whether a model can generate code. It is whether the organization can explain, audit, and consistently enforce the line between allowed defensive use and blocked offensive use. Anthropic’s framework does not solve that industry-wide problem, but it does turn it into something more concrete than generic safety language.
That is useful because many enterprises are already building AI-assisted workflows into code review, vulnerability triage, runbook generation, and incident response. Once those workflows touch real repositories, credentials, cloud consoles, or production logs, vague statements about “responsible AI” stop being enough. Teams need named risk classes, approval paths, fallback behavior, and evidence that a provider can explain why a model accepted one security task and refused another.
The latest Anthropic guidance also lines up with a broader policy backdrop. A June 2 White House executive order on advanced AI innovation and security signaled a more interventionist approach to frontier model oversight. The Record separately reported on July 1 that U.S. export controls on Anthropic’s frontier cyber models were lifted only after the company agreed to new safeguards and coordination steps. Taken together, those developments suggest that model governance is becoming part of production planning for AI-enabled engineering teams.

Practical impact for developers, DevOps, and cloud teams
First, teams using AI for security-adjacent tasks should assume stricter model behavior at the boundary between debugging and offensive research. That means pipeline designers need fallback paths when a model refuses a task, such as handing work to a human reviewer, routing to a different approved tool, or narrowing the prompt to a clearly defensive scope.
Second, provider selection is becoming a governance decision as much as a quality or price decision. If one model vendor now publishes named risk categories and a severity scale for jailbreaks, enterprise buyers will increasingly expect comparable language from others. This is especially relevant for teams already investing in LLMOps, where model behavior has to be monitored and versioned like any other production dependency.
Third, internal AI policies should probably be updated to match the new reality. Security teams can no longer assume that the same model will always be available globally, or that a frontier provider will treat all security prompts the same way over time. Model access, auditability, and refusal behavior now belong in the same operating checklist as secrets handling, CI approvals, and deployment rollback. GravityDevOps readers comparing delivery controls can tie those requirements back to their existing CI/CD tooling choices and to prompt hygiene practices described in our prompt engineering guide.
What remains uncertain
Anthropic’s framework is still a draft, not an industry standard. It is not yet clear whether rival labs, cloud platforms, or regulators will adopt the same severity terms, or whether the categories will prove stable enough for procurement and compliance teams to rely on. It is also unclear how many legitimate security workflows will be caught in the widened safety margin that Anthropic says it intentionally built around Fable 5.
There is another open question for platform leaders: whether clearer model policy language will reduce operational risk, or simply formalize the fact that access to frontier models can change quickly. The answer will matter for teams deciding how much of their security automation should depend on a single hosted model versus a multi-model or self-hosted approach.
Bottom line
Anthropic’s July 2 update matters less as a brand story than as a preview of how frontier model controls may be documented from here. The company has effectively published a first draft of a policy interface for AI-assisted cybersecurity work. For DevOps and platform teams, the immediate takeaway is to review where AI tools sit inside engineering workflows, define fallback paths for refused or restricted tasks, and require clearer control language from model vendors before those tools move deeper into production.
Brief FAQ: Is Anthropic saying defensive coding work should still be allowed? Yes, the company explicitly lists secure coding, debugging, patch management, and incident response as benign or defensive activity it does not intend to block. Is the jailbreak scale an industry standard yet? No, Anthropic describes it as an early draft and is asking for outside feedback. Does this mean model access risk is over? No. The latest update clarifies controls, but it also shows that policy shifts can still affect availability and workflow design.
Sources: Anthropic’s July 2 safeguards and jailbreak framework post, Anthropic’s June 30 Fable 5 redeployment note, The Record on the U.S. lifting Anthropic export controls, and the White House June 2 executive order on advanced AI innovation and security.
