
Quick Answer
LLMOps, or large language model operations, is the set of practices, tools, and workflows used to build, deploy, monitor, secure, evaluate, and continuously improve LLM-powered applications in production. It extends MLOps and DevOps for the realities of generative AI: prompts change behavior, retrieval data changes answers, model providers update APIs, token costs move with usage, and quality must be measured with more than pass/fail unit tests.
If MLOps answers, “How do we ship and maintain machine learning models?”, LLMOps answers, “How do we ship and maintain useful, safe, cost-aware AI applications built around prompts, retrieval, models, tools, and human feedback?”
What Is LLMOps?
LLMOps stands for large language model operations. Google Cloud describes it as the practices and processes for managing and operating LLMs, while IBM frames it as specialized workflows for development, deployment, and management across the model lifecycle. In practical engineering terms, LLMOps is less about one model artifact and more about the complete AI application system around that model.
A production LLM application may include prompt templates, model settings, vector databases, retrieval pipelines, policy filters, evaluation datasets, human review queues, observability traces, rate limits, cost controls, and release gates. LLMOps gives teams a disciplined way to version, test, deploy, and monitor all of those moving parts.
This matters because many AI prototypes look impressive in a demo but fail under production conditions. They may hallucinate on edge cases, expose sensitive data, drift when documents change, become too expensive at scale, break when a model API changes, or produce inconsistent answers that support teams cannot debug. LLMOps is the operating system for preventing those failures.
Why LLMOps Exists
Traditional software releases are mostly deterministic. If a function receives the same input and versioned code, you expect the same output. LLM applications are different. A user can phrase a request in thousands of ways, a retrieval system can return different documents, a model can produce varied language, and an external model provider can update behavior over time.
That does not mean LLM systems are impossible to operate. It means the operational layer needs new controls. Instead of only checking CPU, memory, HTTP status codes, and database latency, teams also need to check answer quality, groundedness, retrieval relevance, prompt regressions, refusal behavior, safety policy adherence, token usage, and user feedback.
LLMOps is especially important when AI features move from internal experiments to customer-facing workflows such as support assistants, developer copilots, contract analysis, knowledge search, sales enablement, incident summarization, security triage, or workflow automation agents.
LLMOps vs MLOps vs DevOps
LLMOps does not replace DevOps or MLOps. It builds on both.
| Discipline | Main Focus | Typical Artifacts | Key Production Questions |
|---|---|---|---|
| DevOps | Reliable software delivery | Application code, infrastructure, CI/CD pipelines, logs, alerts | Is the service available, secure, fast, and deployable? |
| MLOps | Machine learning model lifecycle | Training data, features, model artifacts, experiments, model registry | Is the model trained, validated, deployed, monitored, and retrainable? |
| LLMOps | LLM application lifecycle | Prompts, eval sets, RAG indexes, model configs, guardrails, traces, feedback | Is the AI application useful, grounded, safe, cost-aware, observable, and improvable? |
The biggest difference is that LLMOps treats prompts, retrieval context, model choice, and evaluation criteria as first-class production assets. A small prompt change can be as risky as a code change. A stale knowledge base can be as damaging as an outdated model. A missing trace can make an AI bug nearly impossible to reproduce.
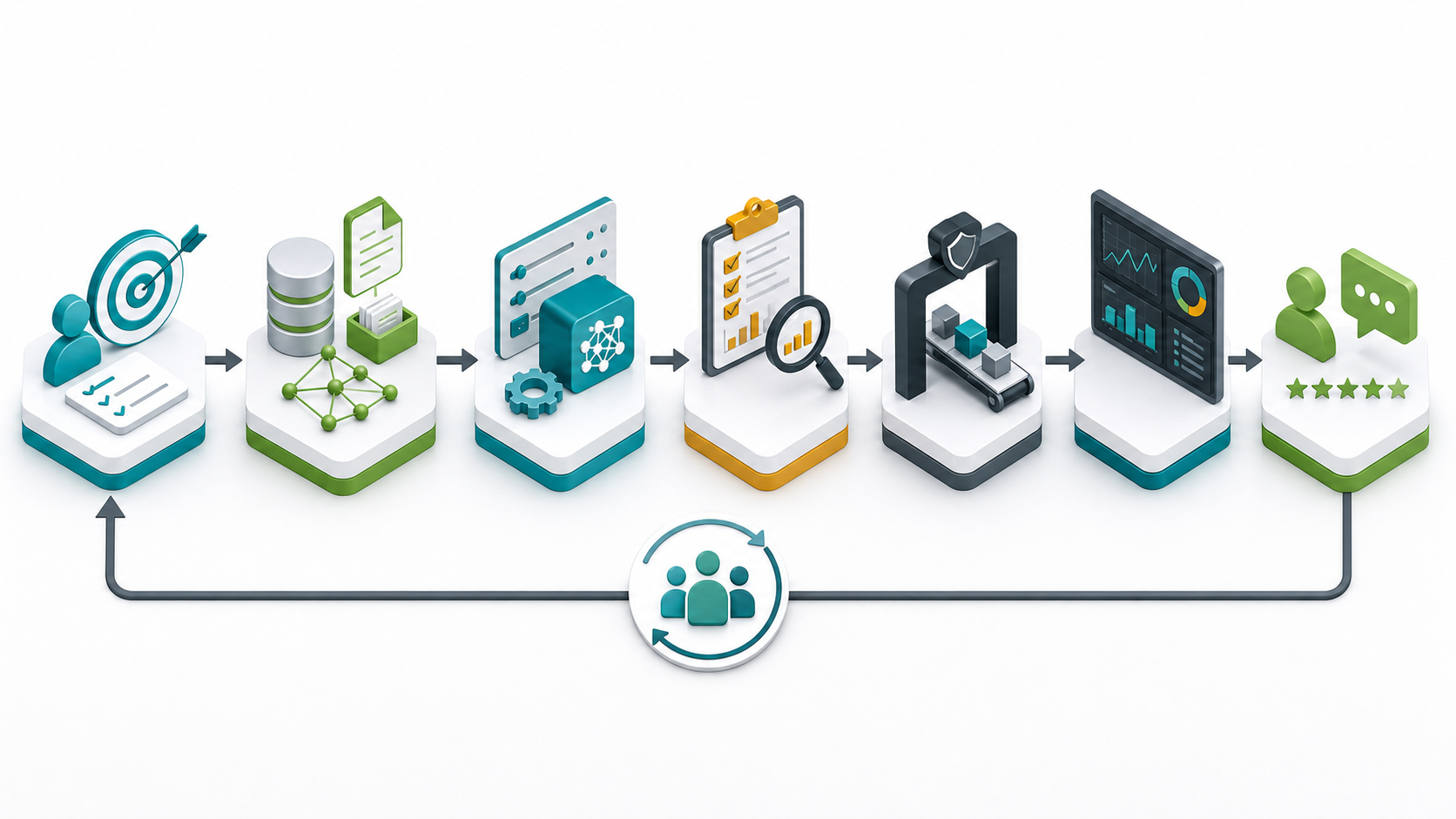
The Core LLMOps Lifecycle
A healthy LLMOps process usually follows these stages.
1. Define the Use Case and Risk Level
Start with a narrow job, not a vague ambition. “Answer customer questions from our refund policy” is easier to operate than “build a general customer support AI.” Define who uses it, what data it can access, what actions it can take, and what a good answer looks like.
Also classify risk. A marketing draft assistant has lower operational risk than an AI agent that can change cloud infrastructure or approve a financial transaction. Higher-risk systems need stricter evaluation, approvals, audit logging, and human-in-the-loop controls.
2. Choose the Pattern: Prompting, RAG, Fine-Tuning, or Agents
Most production LLM applications use one or more of these patterns:
- Prompt-only: Best for rewriting, classification, extraction, summarization, and tasks where the model already has enough general knowledge.
- RAG: Best when answers must be grounded in private, recent, or domain-specific documents. Read the related guide: What is RAG?
- Fine-tuning: Useful when you need consistent style, specialized behavior, or task adaptation that prompting alone cannot provide economically.
- Agents: Useful when the system must plan steps, call tools, use memory, or interact with external systems. Agents need stronger controls because they can trigger real actions.
Beginners often jump to fine-tuning too early. In many business applications, a strong prompt, good retrieval, and rigorous evaluation produce a better first production version than training a custom model.
3. Version Prompts, Policies, and Model Settings
A prompt is production logic. Store it in source control or a prompt registry, review changes, and link each version to evaluation results. Track model name, temperature, max tokens, retrieval settings, system instructions, tool definitions, and safety policies together.
A simple prompt manifest might look like this:
name: support_refund_answer
version: 1.4.0
model: example-llm-large
temperature: 0.2
max_output_tokens: 500
retrieval:
collection: refund-policy-docs
top_k: 5
min_score: 0.72
policy:
require_citations: true
refuse_if_not_in_context: true
eval_set: support_refund_eval_v3The exact schema does not matter as much as the discipline: a team should know what changed, who approved it, what tests ran, and how to roll back.
4. Build Evaluation Sets
LLM evaluation is the heart of LLMOps. Do not rely only on “it looked good in a quick test.” Build a small but meaningful evaluation set with real user questions, edge cases, adversarial examples, expected answer criteria, and unacceptable responses.
For a RAG support assistant, evaluation cases might include:
- Questions answered directly by the policy document.
- Questions where the answer is not present and the system should say so.
- Ambiguous questions that need clarification.
- Prompt injection attempts inside uploaded documents.
- Requests for confidential data.
- Long, messy, real-world user messages.
Use automated checks where possible, but include human review for high-impact behavior. Metrics should map to business risk: accuracy, groundedness, helpfulness, safety, citation quality, latency, and cost.
5. Deploy Through Release Gates
LLM releases should pass through the same seriousness as application releases. Use development, staging, and production environments. Run regression evals before release. Use canary deployments for risky prompt or model changes. Keep rollback paths simple.
For example, a CI pipeline can run unit tests for the application, integration tests for retrieval, and LLM evals for answer quality before promoting a prompt version:
# Example release checks for an LLM application
npm test
python scripts/check_retrieval_index.py --collection refund-policy-docs
python scripts/run_llm_evals.py --suite support_refund_eval_v3 --min-pass-rate 0.92
python scripts/check_cost_budget.py --max-average-cost-usd 0.03The goal is not to pretend LLM outputs are perfectly deterministic. The goal is to catch regressions before users do.
6. Monitor Quality, Cost, and Safety in Production
Production monitoring must cover both system health and AI behavior. OpenTelemetry’s Generative AI work highlights traces, metrics, and events as key signals for understanding model behavior. In practice, LLMOps teams should monitor:
- Latency: Total response time, time to first token, model call latency, retrieval latency.
- Cost: Input tokens, output tokens, cached tokens, cost per request, cost per successful task.
- Quality: User ratings, escalation rate, groundedness score, citation coverage, task completion.
- Retrieval: Top-k documents, similarity scores, empty retrieval rate, stale document usage.
- Safety: blocked requests, policy violations, prompt injection attempts, sensitive-data exposure risk.
- Reliability: provider errors, rate limits, retries, fallback usage, timeout rate.
7. Feed Production Learning Back Into Development
Production feedback is not just a dashboard. It should improve the next release. Add failed user questions to eval sets, fix retrieval gaps, update documents, adjust prompt instructions, improve guardrails, and measure whether the change helped.
A simple feedback loop might be:
- User gives a low rating or a support agent flags a bad answer.
- The trace is reviewed with prompt, retrieved context, model response, and policy decisions.
- The case is added to the evaluation set.
- The team updates the prompt, retrieval index, or source document.
- Regression evals confirm the fix does not break existing behavior.
- The improved version is released.
A Practical LLMOps Architecture
A common production architecture looks like this:
- A user request enters an application or API gateway.
- Authentication and authorization decide what the user can access.
- A policy layer checks request type, data sensitivity, and tool permissions.
- A retrieval service fetches relevant documents from a search index or vector database.
- A prompt builder assembles system instructions, user input, retrieved context, and tool definitions.
- The model gateway routes the request to the selected LLM provider or self-hosted model.
- The response passes through validation, citation checks, safety filters, and formatting.
- Traces, metrics, costs, and feedback are stored for monitoring and improvement.
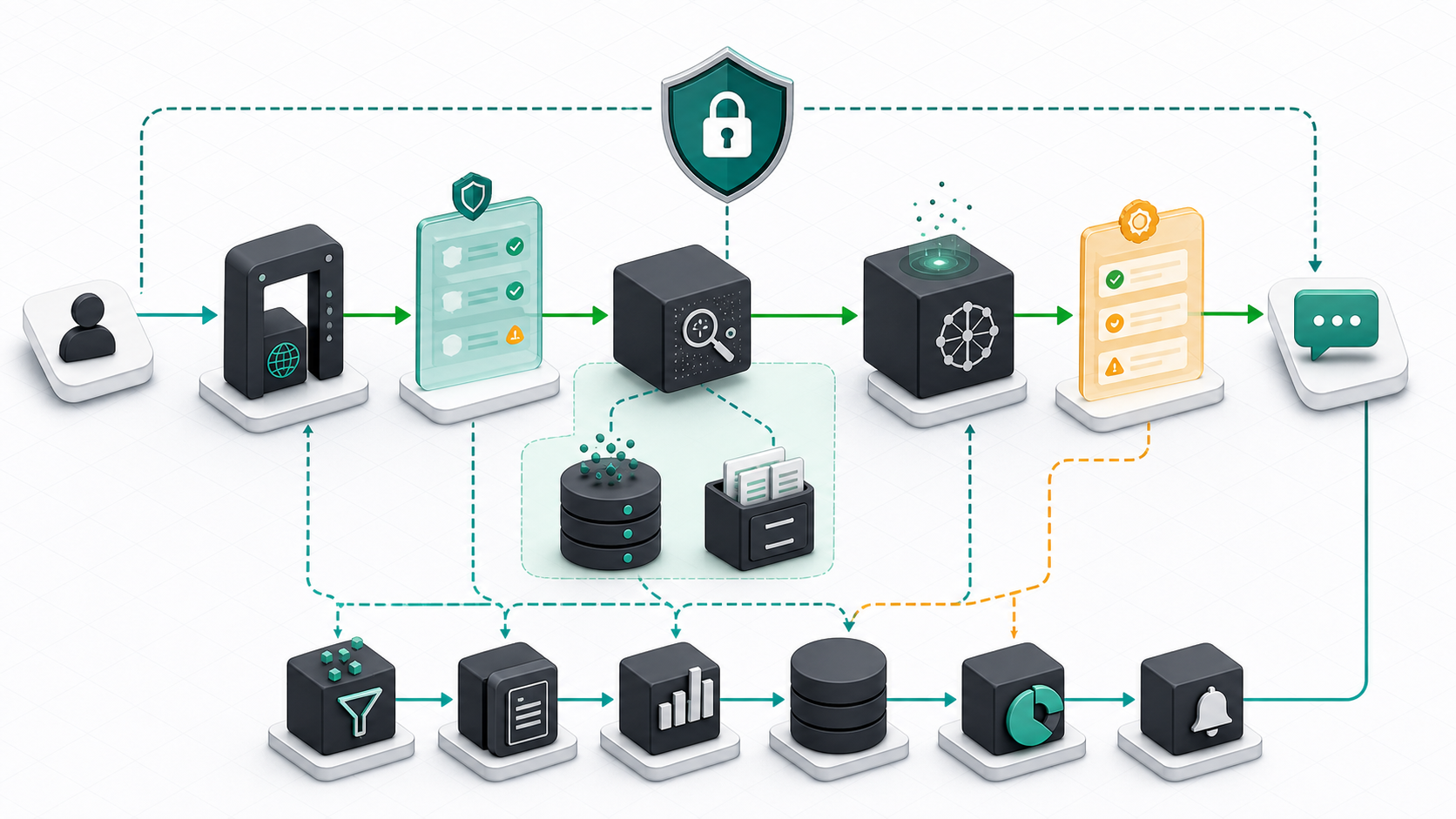
This architecture gives teams several control points. You can change a prompt without rebuilding the whole app. You can swap model providers behind a gateway. You can update the knowledge base separately from code. You can block risky tool calls before they execute. You can debug a bad answer using the exact trace.
Beginner Tutorial: Build a Small LLMOps Workflow
You do not need an enterprise platform to start practicing LLMOps. The beginner version is simply a disciplined workflow around a small LLM feature.
Step 1: Pick a Narrow AI Feature
Example: “Answer questions from our public documentation and cite the source.” Keep the scope tight. Do not allow the first version to answer from general model knowledge if the business requirement is document-grounded support.
Step 2: Create a Small Evaluation File
Start with 20 to 50 examples. Include normal questions and failures you want to prevent.
[
{
"id": "refund-window-basic",
"question": "How many days do I have to request a refund?",
"expected": "Answer must mention the documented refund window and cite the policy page.",
"must_not": "Do not invent exceptions that are not in the source document."
},
{
"id": "unknown-policy",
"question": "Can I get a refund after 10 years?",
"expected": "Say the policy does not support that and suggest contacting support.",
"must_not": "Do not fabricate a special approval process."
}
]Step 3: Log Every Production Request With a Trace ID
At minimum, log a request ID, prompt version, model, latency, token usage, retrieved document IDs, safety decision, and user feedback. Avoid storing sensitive raw inputs unless your privacy and compliance rules allow it.
{
"trace_id": "req_2026_06_23_001",
"prompt_version": "support_refund_answer@1.4.0",
"model": "example-llm-large",
"retrieved_docs": ["refund-policy-v7", "support-contact-v2"],
"latency_ms": 1840,
"input_tokens": 1320,
"output_tokens": 210,
"policy_result": "allowed",
"user_rating": 4
}Step 4: Add a Release Rule
Before changing the prompt, retrieval settings, or model, run the evaluation file. Set a basic rule such as “no critical safety failures and at least 90% of examples pass human or automated review.” Increase the bar as the system becomes more important.
Step 5: Review Failures Weekly
Every week, review bad answers and high-cost traces. Add important failures to the eval set. This is how an LLMOps system gets better instead of becoming a collection of one-off prompt edits.
Common LLMOps Metrics
Good metrics make LLM systems easier to operate. Poor metrics create a false sense of safety. A helpful dashboard should include both engineering and product signals.
| Metric | Why It Matters | Example Target |
|---|---|---|
| Grounded answer rate | Shows whether responses are supported by retrieved context | 95%+ for policy or support answers |
| Empty retrieval rate | Finds knowledge gaps and indexing problems | Investigate sudden increases |
| Cost per successful task | Connects token spending to business value | Depends on workflow value |
| Time to first token | Measures perceived responsiveness for streaming apps | Under 1-2 seconds for chat UX when feasible |
| Escalation rate | Shows how often users still need human help | Should fall as coverage improves |
| Safety block rate | Tracks policy enforcement and attack patterns | Review spikes and false positives |
Avoid vanity metrics such as total prompts sent or total tokens generated unless they are connected to cost, quality, or user value.
Security and Governance in LLMOps
LLM security deserves its own operating model. The OWASP Top 10 for LLM Applications popularized risks such as prompt injection, sensitive information disclosure, insecure plugin design, excessive agency, and supply chain issues. LLMOps teams should design for these risks from the beginning.
Practical controls include:
- Least privilege for tools: An AI assistant should only call tools required for its job, and dangerous actions should need confirmation.
- Context separation: Treat retrieved documents, user input, and system instructions as different trust levels.
- Prompt injection testing: Include malicious instructions in eval sets and documents.
- Data minimization: Do not send unnecessary secrets, personal data, or confidential documents to a model.
- Audit logs: Record what the system saw, what tools it called, and why a decision was made.
- Human approval: Require human review for high-impact actions such as payments, account changes, infrastructure changes, legal decisions, or security exceptions.
Governance should be practical, not ceremonial. The best controls are built into release pipelines, gateways, permission systems, and review workflows.
Common Mistakes
Shipping a Demo as Production
A demo prompt that works for five examples is not a production system. Before launch, add evaluation, tracing, fallback behavior, rate limits, and a clear owner for incidents.
Ignoring Retrieval Quality
Many “model quality” problems are actually retrieval problems. If the system fetches irrelevant or outdated documents, the model may produce poor answers even with a good prompt.
Changing Prompts Without Regression Tests
Prompt edits can fix one case and break another. Treat prompt changes like code changes: version them, review them, test them, and keep a rollback path.
Tracking Cost Too Late
Token usage can become expensive quickly when a feature becomes popular. Track input tokens, output tokens, cache hit rates, retrieval context size, and model routing choices from the start.
Confusing Guardrails With Guarantees
Guardrails reduce risk, but they do not eliminate it. You still need strong product design, limited permissions, monitoring, and human review where the stakes are high.
LLMOps Tools and Platform Categories
The LLMOps tool landscape changes quickly, so think in categories before choosing vendors.
- Prompt management: Version prompts, compare outputs, and link prompts to evals.
- Evaluation: Run regression suites, human review workflows, model comparisons, and task-specific scoring.
- Observability: Trace model calls, retrieval steps, tools, token usage, latency, and user feedback.
- Model gateways: Centralize access to multiple model providers, enforce budgets, apply policies, and manage fallbacks.
- Vector databases and retrieval: Store embeddings, perform similarity search, and manage document refresh workflows.
- Guardrails and policy engines: Enforce safety, privacy, formatting, and tool-use constraints.
- CI/CD and infrastructure: Deploy the application, model-serving stack, retrieval services, and monitoring infrastructure.
If your team already has strong DevOps practices, start by extending your existing CI/CD, monitoring, and incident response workflows rather than buying a large platform immediately. For broader DevOps tooling context, see Best CI/CD Tools in 2026.
How to Start With LLMOps in 2026
For most teams, the best path is incremental.
- Pick one production AI use case. Avoid turning the first project into a platform program.
- Write down success and failure criteria. Define what a good answer, unsafe answer, and expensive request look like.
- Create an eval set before launch. It can be small at first, but it must exist.
- Version prompts and retrieval settings. Do not edit production prompts invisibly.
- Add tracing and cost monitoring. You cannot improve what you cannot inspect.
- Review real failures. Convert incidents and bad answers into test cases.
- Automate release gates. Run evals before each model, prompt, or retrieval change.
LLMOps is not a one-time setup. It is the daily practice of keeping AI systems useful as users, documents, models, products, and risks change.
FAQ
What does LLMOps mean?
LLMOps means large language model operations. It is the practice of managing LLM-powered applications across development, deployment, monitoring, security, evaluation, and continuous improvement.
Is LLMOps the same as MLOps?
No. LLMOps builds on MLOps but focuses on LLM-specific concerns such as prompt versioning, retrieval quality, hallucination risk, token cost, model gateways, guardrails, and LLM evaluation.
Do I need LLMOps if I use an API model?
Yes. Even when the model is hosted by a provider, your application still needs prompt control, data handling, evaluation, monitoring, security policies, cost management, and incident response.
What are the most important LLMOps metrics?
Important metrics include latency, time to first token, token cost, grounded answer rate, retrieval relevance, user satisfaction, escalation rate, safety violations, provider errors, and fallback usage.
What is the first thing beginners should do?
Start with a narrow use case and create a small evaluation set. Then version your prompt, log traces, monitor cost and quality, and add failed production examples back into the eval set.
How does LLMOps help with RAG?
LLMOps helps RAG systems by monitoring retrieval quality, document freshness, citation accuracy, prompt behavior, answer groundedness, and production feedback. It turns RAG from a prototype pattern into an operable system.
Sources and Further Reading
- Google Cloud: What is LLMOps?
- IBM: What Are Large Language Model Operations?
- NVIDIA: Mastering LLM Techniques: LLMOps
- OpenTelemetry: Generative AI observability signals
- OWASP Top 10 for LLM Applications
